-
[글또] 아마존 레드시프트(AWS Redshift) 이해하기엔지니어가 되자/Data Engineering 2021. 8. 29. 23:20

회사에서 사용하고 있는 데이터 웨어하우스인 AWS Redshift를 아무런 고민없이 사용하다가 어떻게 돌아가는지 궁금해서 한번 알아보았습니다. 김용우 님의 글을 주로 참고했습니다. (링크)
레드시프트(AWS Redshift)
- 레드시프트는 아마존 웹서비스에서 제공하는 대용량 병렬처리 관계형 데이터 웨어하우스 서비스
- 일반적인 트랜잭션을 위한 데이터베이스보다는 분석목적의 데이터 저장소에 가깝다
- 병렬처리 관계형 데이터베이스로 리더 - 팔로워 노드 기반의 연산을 수행
- 외부 서비스와의 통신은 오로지 리더 노드(Leader Node)에서만 이루어지게 됨
- 데이터의 업데이트는 S3를 경유하여 이루어짐

Redshift Simple Architecture - Compute Node의 경우 이론상 여러개로 무한 증식이 가능
- 기존 사용하던 리더 - 팔로워 노드 구조에서 노드를 늘리는 작업을 수행하고 싶을 경우에는 별도의 레플리카를 구성한 뒤에
그 해당 레플리카의 구성이 끝난 뒤 복제된 리더노드 엔드포인트를 바라보도록 설정을 변경한 뒤 기존 리더/팔로워를 삭제

Redshift의 수평적 스케일업 과정 레드시프트의 경우 스케일업을 하는 경우 기존 리더노드를 바라보는 팔로워 노드들의 갯수를 추가하는 방식이 아니라 새로운 레플리카를 구성한 뒤에 리더노드를 바라보는 엔드포인트만 변경해주는 방식이다. 그 과정 중에는 CUD 명령어는 수행이 중지되고 Read Only로 변경되어 쿼리만 가능하도록 변경해준다. 이렇게하면 무중단 데이터베이스 운영이 가능하기 때문이 아닐까 싶다. 기존 리더 노드에 클러스터를 추가하는 방식으로 진행할 경우 업데이트 과정중에 들어오는 쿼리들을 처리하는 데에 방해가 될 수도 있을 것 같다.
그러면 레드시프트는 어떻게 데이터를 분산하여 처리할까? 레드시프트가 데이터를 분산 처리하는 방식은 크게 3가지가 있다. 1) 각 레코드가 개별 연산 노드에 균등하게 분산/저장 되는 Even 방식 2) 명시적으로 지정한 키에 따라 분산하는 Dist Key 방식 3) 모든 레코드를 모든 연산 노드에 분산하는 All 방식이다.
All 방식을 사용할 경우 연산노드 추가하는 과정에서 굳이 레플리카를 만들어 변경하지 않더라도 무중단 변경배포가 가능하다. 모든 컴퓨팅 노드에 데이터가 분산하여 저장되기 때문이다. 하지만 레드시프트에서 가장 기본적으로 수행되는 분산 방식은 Even방식을 채택하고 있다.
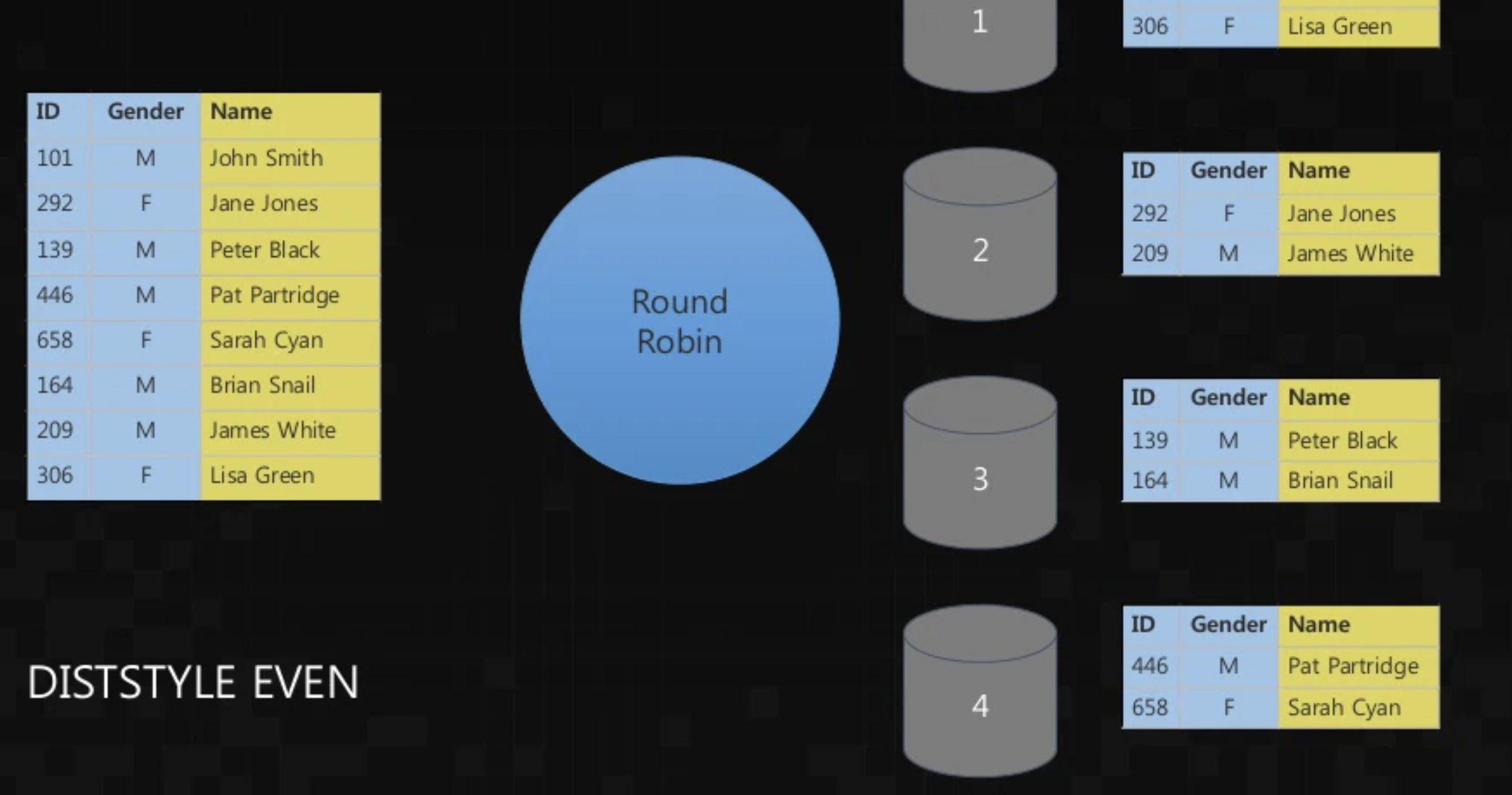
라운드로빈으로 데이터를 나누는 Even 방식의 분산 처리 레드시프트의 데이터 업데이트 과정을 살펴보면 S3를 통한 데이터 업데이트가 된다. 내가 회사에서 사용하고 있는 운영환경에서도 S3에 pandas로 정제한 데이터를 csv로 떨어뜨린 뒤, 이를 레드시프트에 copy하는 방식으로 테이블 생성/갱신을 수행하고 있어서 S3를 빼놓고 생각해본 적이 없었던 것 같다. 그렇다고 아래의 도식을 살펴보면 S3만이 필수적인 방법은 아닌 것 같다.

Redshift 파이프라인 하나의 슬라이스(연산 노드 내의 최소 처리 단위, 1개 이상의 슬라이스가 연산 노드 내에 존재 가능)가 처리할 수 있는 최대는 S3 파일 1개이다! 그렇기 때문에 다큐먼트 상에서도 병렬 다중처리를 하여 속도를 높이고 싶을 경우 S3내에 파일을 나누어서 관리를 해야한다고 한다. 레드시프트는 웨어하우스 목적으로 주로 사용했고 이를 백업하기 위한 레이크가 별도로 필요했는데 S3를 통한 업로드를 주요 파이프로 사용하면서 자연스럽게 데이터 레이크를 구성하는 효과를 얻게 되는 것 같다.
업데이트와 삭제에도 쿼리 속도를 보장하기 위한 장치들도 있다. 실제 회사 운영환경에서도 배치로 Vaccum이라는 명령어를 주기적으로 수행해주고 있는데, 무엇을 하는 것인지는 이번에 알아보면서 제대로 알게 되었다. 새로 업데이트 된 데이터의 경우 주요 키를 기반으로 정렬되어있지 않은 상태로 데이터가 들어오게 되는데, Vaccum 수행을 통해 삭제된 데이터와 업데이트된 데이터들에 대해 쿼리시 속도 보장을 위해 sort해주는 연산이라고 이해하면 될 것 같다.

다른 DB와 어떻게 다른가?
- 분석 목적이 주요한 OLAP 데이터베이스
- 여러가지 Window Function을 지원 (MySQL 미지원)
- rank, dense_rank, row_num, lag 등
- S3 데이터 레이크를 활용한 백업 관리
- 스냅샷을 이용한 백업관리가 가능한 기존 AWS 오로라 MySQL 디비에 비해 백업 관리 기능이 더 충실
- 처리 속도
- 일반 OLTP 목적 데이터베이스와 비교하여 속도를 비교하는 것은 의미가 없을 것 같고.. 그렇다고 사용하는 다른 대용량
데이터베이스가 없어서 비교군이 없어서 좀 아쉽다
- 그래도 약 2~300만건에 해당하는 테이블 풀스캔이 3~4초 이내로 일반 MySQL RDB 쿼리하는 속도를 감안해보면 매우 빠른편
레퍼런스:
https://www.slideshare.net/awskorea/amazon-redshift-deep-dive
Amazon Redshift의 이해와 활용 (김용우) - AWS DB Day
2016년 4월 27일 DB Day 에서 김용우 솔루션즈 아키텍트 께서 발표하신 “Amazon Redshift의 이해와 활용 “ 발표자료입니다.
www.slideshare.net
데이터 웨어하우스 | Redshift | Amazon Web Services
어떠한 데이터 웨어하우스로도 이렇게 손쉽게 모든 데이터에 대한 새로운 인사이트를 얻을 수 없습니다. Redshift를 사용하면 표준 SQL을 통해 데이터 웨어하우스, 운영 데이터베이스 및 데이터 레
aws.amazon.com
반응형'엔지니어가 되자 > Data Engineering' 카테고리의 다른 글
AWS EC2에 Docker 환경 배포 작업기 - WAS(Django) / Web Server(Nginx) / Mysql DB (0) 2024.01.02 [글또] 스칼라와 친해지기 (개념/설치/문법) (0) 2021.11.07 [글또] Spark 정리하기(2/2) - Dataframe, Dataset (0) 2021.10.12 [글또] Spark 정리하기 (1/2) - 개념, RDD (0) 2021.09.12 [개발지식] MSA(Micro Service Architecture)란? (0) 2021.06.14